 Écrit par
Hasnen
Écrit par
Hasnen
L’intelligence artificielle (IA) générative a fait des progrès considérables, mais ses modèles, comme les grands modèles de langage (LLM), présentent des limites : connaissances parfois obsolètes, tendance à générer des informations plausibles mais incorrectes (« hallucinations »), et réponses parfois génériques.
Pour pallier ces défauts, une technique appelée « Retrieval-Augmented Generation » (RAG) a été développée, ou encore en français la Génération Augmentée de Récupération.
Imaginez un juge dans une salle d’audience. Il s’appuie sur sa compréhension générale du droit pour rendre des décisions. Cependant, pour des cas spécifiques nécessitant une expertise particulière, il demande à ses greffiers de consulter la bibliothèque juridique à la recherche de précédents et de jurisprudences spécifiques.
De manière similaire, les LLM peuvent répondre à une grande variété de requêtes, mais pour fournir des réponses fiables et précises basées sur des informations spécifiques et à jour, ils ont besoin d’accéder à ces informations externes. La RAG agit comme ce « greffier » pour l’IA.
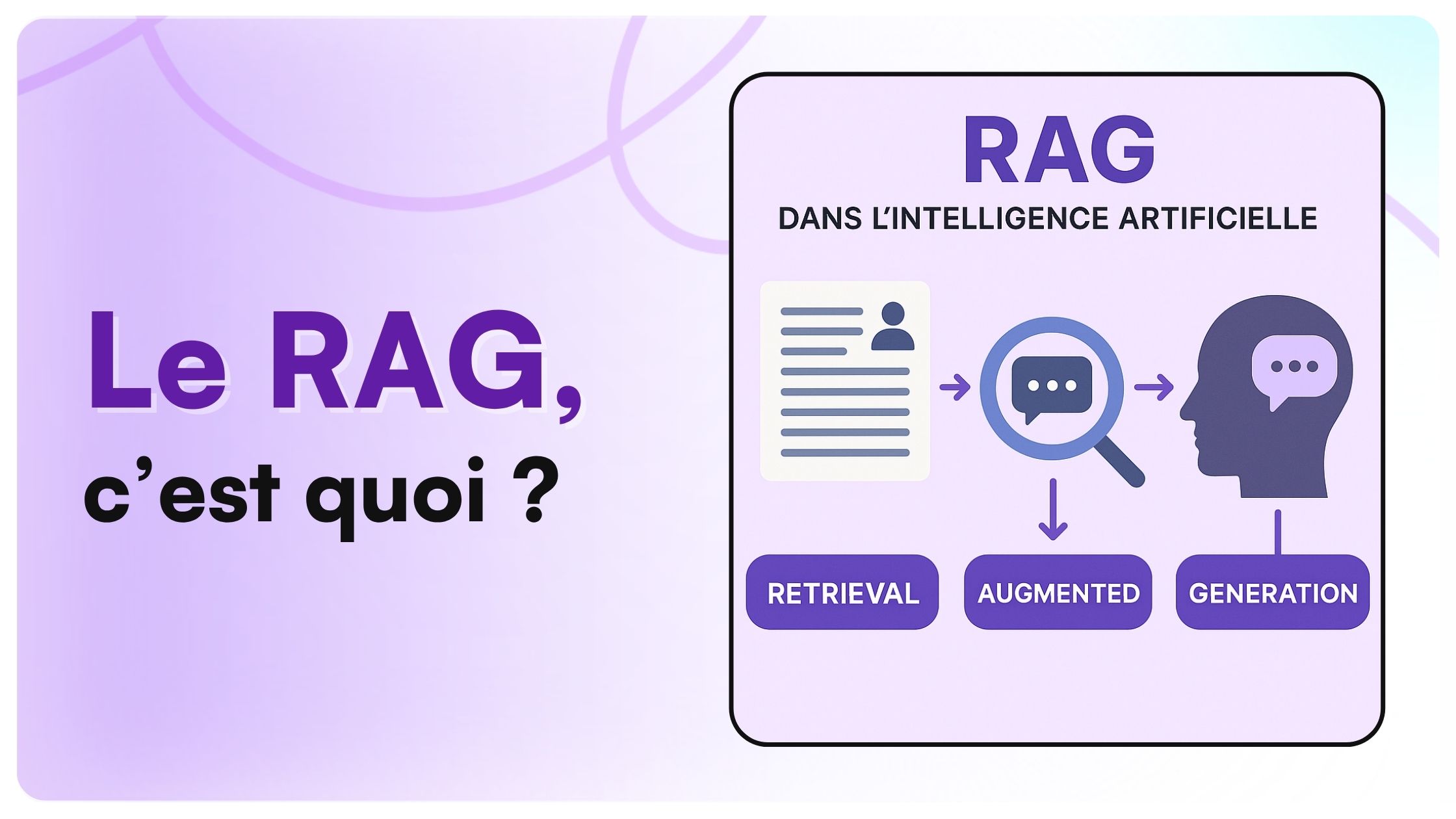
La RAG est une technique d’IA qui améliore la précision et la fiabilité des modèles d’IA générative en complétant leurs connaissances internes par des informations récupérées en temps réel à partir de sources de données externes spécifiées.
La RAG répond directement aux limitations inhérentes des LLM. En intégrant un mécanisme de récupération d’informations avant la génération de la réponse, elle offre plusieurs avantages clés :
Le processus RAG combine la récupération d’informations et la génération de texte en plusieurs étapes :
La préparation et l’indexation des données de la base de connaissances externe sont cruciales pour l’efficacité du processus de récupération. Des outils comme LangChain sont souvent utilisés pour orchestrer ces étapes complexes.
Bien que le terme « RAG » soit récent, l’idée de combiner recherche d’information et traitement du langage naturel (NLP) remonte aux années 1970 avec les premiers systèmes de question-réponse. Des services comme Ask Jeeves (maintenant Ask.com) dans les années 1990 et Watson d’IBM, célèbre pour sa victoire au jeu télévisé Jeopardy! en 2011, ont popularisé ces approches.
Le terme « Retrieval-Augmented Generation » (RAG) a été spécifiquement introduit en 2020 dans un article de chercheurs de Facebook AI Research (maintenant Meta AI), University College London et New York University, dont Patrick Lewis était l’auteur principal. Ils cherchaient à intégrer plus efficacement des connaissances externes dans les LLM pour améliorer leur fiabilité sur des tâches nécessitant des informations précises.
L’acronyme « RAG », bien que peu flatteur, s’est imposé faute de meilleure alternative au moment de la publication. Depuis, cette approche a été largement adoptée et étendue par la communauté de recherche et l’industrie.
Il est utile de comparer la RAG à d’autres techniques d’adaptation des LLM :
| Approche | Avantages clés | Limites principales |
|---|---|---|
| RAG | Exploite des sources externes à jour, Coûts réduits, Personnalisation facile | Difficulté d’intégration potentielle, Dépendance à la qualité des données |
| Fine-tuning | Spécialisation poussée du modèle, Cohérence stylistique | Coûts de réentraînement élevés, Mises à jour complexes, Risque d’oubli |
| Modèles long contexte | Conservation étendue du contexte conversationnel, Interactions naturelles | Consommation mémoire importante, Difficulté de maintenance, Coûts élevés |
La RAG est particulièrement avantageuse lorsque l’accès à des informations dynamiques et factuelles est primordial.
La capacité de la RAG à « converser » avec des référentiels de données ouvre un large éventail d’applications :
De nombreuses entreprises technologiques majeures, dont AWS, IBM, Google, Microsoft, NVIDIA, Oracle et Pinecone, adoptent et proposent des solutions basées sur la RAG.
Pour déployer la RAG efficacement :
La RAG est une étape clé, mais l’évolution continue vers des systèmes d’IA plus autonomes, parfois appelés « agentic AI », où les LLM, les bases de connaissances et d’autres outils sont orchestrés dynamiquement pour accomplir des tâches complexes.
La RAG restera probablement une composante fondamentale de ces systèmes futurs.
La Retrieval-Augmented Generation (RAG) transforme l’IA générative en la rendant plus fiable, précise et connectée au monde réel.
En combinant la puissance de génération des LLM avec la rigueur de la recherche d’informations, elle permet de créer des applications IA plus utiles et dignes de confiance, que ce soit pour améliorer le service client, faciliter l’accès à l’information spécialisée ou optimiser les processus métier.
Bien qu’encore jeune, la RAG est une technologie clé pour exploiter pleinement le potentiel de l’IA générative en entreprise et au-delà.
Abonne-toi à notre newsletter 👇



